Screen Scraping with BeautifulSoup and lxml

Please enjoy this — a free Chapter of the Python network programming book that I revised for Apress in 2010!
I completely rewrote this chapter for the book's second edition, to feature two powerful libraries that have appeared since the book first came out. I show how to screen-scrape a real-life web page using both BeautifulSoup and also the powerful lxml library (their web sites are here and here).
I chose this chapter for release because screen scraping is often the first network task that a novice Python programmer tackles. Because this material is oriented towards beginners, it explains the entire process — from fetching web pages, to understanding HTML, to querying for specific elements in the document.
Program listings are available for this chapter in Python 2. Let me know if you have any questions!
Most web sites are designed first and foremost for human eyes. While well-designed sites offer formal APIs by which you can construct Google maps, upload Flickr photos, or browse YouTube videos, many sites offer nothing but HTML pages formatted for humans. If you need a program to be able to fetch its data, then you will need the ability to dive into densely formatted markup and retrieve the information you need—a process known affectionately as screen scraping.
In one's haste to grab information from a web page sitting open in your browser in front of you, it can be easy for even experienced programmers to forget to check whether an API is provided for data that they need. So try to take a few minutes investigating the site in which you are interested to see if some more formal programming interface is offered to their services. Even an RSS feed can sometimes be easier to parse than a list of items on a full web page.
Also be careful to check for a “terms of service” document on each site. YouTube, for example, offers an API and, in return, disallows programs from trying to parse their web pages. Sites usually do this for very important reasons related to performance and usage patterns, so I recommend always obeying the terms of service and simply going elsewhere for your data if they prove too restrictive.
Regardless of whether terms of service exist, always try to be polite when hitting public web sites. Cache pages or data that you will need for several minutes or hours, rather than hitting their site needlessly over and over again. When developing your screen-scraping algorithm, test against a copy of their web page that you save to disk, instead of doing an HTTP round-trip with every test. And always be aware that excessive use can result in your IP being temporarily or permanently blocked from a site if its owners are sensitive to automated sources of load.
Fetching Web Pages
Before you can parse an HTML-formatted web page, you of course have to acquire some. Chapter 9 provides the kind of thorough introduction to the HTTP protocol that can help you figure out how to fetch information even from sites that require passwords or cookies. But, in brief, here are some options for downloading content.
From the Future
If you need a simple way to fetch web pages before scraping them, try Kenneth Reitz's requests library!
The library was not released until after the book was published, but has already taken the Python world by storm. The simplicity and convenience of its API has made it the tool of choice for making web requests from Python.
- You can use
urllib2, or the even lower-levelhttplib, to construct an HTTP request that will return a web page. For each form that has to be filled out, you will have to build a dictionary representing the field names and data values inside; unlike a real web browser, these libraries will give you no help in submitting forms. - You can to install
mechanizeand write a program that fills out and submits web forms much as you would do when sitting in front of a web browser. The downside is that, to benefit from this automation, you will need to download the page containing the form HTML before you can then submit it—possibly doubling the number of web requests you perform! - If you need to download and parse entire web sites, take a look at the Scrapy project, hosted at
scrapy.org, which provides a framework for implementing your own web spiders. With the tools it provides, you can write programs that follow links to every page on a web site, tabulating the data you want extracted from each page. - When web pages wind up being incomplete because they use dynamic JavaScript to load data that you need, you can use the
QtWebKitmodule of thePyQt4library to load a page, let the JavaScript run, and then save or parse the resulting complete HTML page. - Finally, if you really need a browser to load the site, both the Selenium and Windmill test platforms provide a way to drive a standard web browser from inside a Python program. You can start the browser up, direct it to the page of interest, fill out and submit forms, do whatever else is necessary to bring up the data you need, and then pull the resulting information directly from the DOM elements that hold them.
These last two options both require third-party components or Python modules that are built against large libraries, and so we will not cover them here, in favor of techniques that require only pure Python.
For our examples in this chapter, we will use the site of the United States National Weather Service, which lives at www.weather.gov.
Among the better features of the United States government is its having long ago decreed that all publications produced by their agencies are public domain. This means, happily, that I can pull all sorts of data from their web site and not worry about the fact that copies of the data are working their way into this book.
Of course, web sites change, so the online source code for this chapter includes the downloaded web page on which the scripts in this chapter are designed to work. That way, even if their site undergoes a major redesign, you will still be able to try out the code examples in the future. And, anyway—as I recommended previously—you should be kind to web sites by always developing your scraping code against a downloaded copy of a web page to help reduce their load.
Downloading Pages Through Form Submission
The task of grabbing information from a web site usually starts by reading it carefully with a web browser and finding a route to the information you need. Figure 10–1 shows the site of the National Weather Service; for our first example, we will write a program that takes a city and state as arguments and prints out the current conditions, temperature, and humidity. If you will explore the site a bit, you will find that city-specific forecasts can be visited by typing the city name into the small “Local forecast” form in the left margin.

Figure 10–1. The National Weather Service web site
(click to enlarge)
When using the urllib2 module from the Standard Library, you will have to read the web page HTML manually to find the form. You can use the View Source command in your browser, search for the words “Local forecast,” and find the following form in the middle of the sea of HTML:
<form method="post" action="http://forecast.weather.gov/zipcity.php" ...> ... <input type="text" id="zipcity" name="inputstring" size="9" value="City, St" onfocus="this.value='';" /> <input type="submit" name="Go2" value="Go" /> </form>
The only important elements here are the <form> itself and the <input> fields inside; everything else is just decoration intended to help human readers.
This form does a POST to a particular URL with, it appears, just one parameter: an inputstring giving the city name and state. Listing 10–1 shows a simple Python program that uses only the Standard Library to perform this interaction, and saves the result to phoenix.html.
Listing 10–1. Submitting a Form with “urllib2”
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 10 - fetch_urllib2.py # Submitting a form and retrieving a page with urllib2 import urllib, urllib2 data = urllib.urlencode({'inputstring': 'Phoenix, AZ'}) info = urllib2.urlopen('http://forecast.weather.gov/zipcity.php', data) content = info.read() open('phoenix.html', 'w').write(content)
On the one hand, urllib2 makes this interaction very convenient; we are able to download a forecast page using only a few lines of code. But, on the other hand, we had to read and understand the form ourselves instead of relying on an actual HTML parser to read it. The approach encouraged by mechanize is quite different: you need only the address of the opening page to get started, and the library itself will take responsibility for exploring the HTML and letting you know what forms are present. Here are the forms that it finds on this particular page:
>>> import mechanize >>> br = mechanize.Browser() >>> response = br.open('http://www.weather.gov/') >>> for form in br.forms(): ... print '%r %r %s' % (form.name, form.attrs.get('id'), form.action) ... for control in form.controls: ... print ' ', control.type, control.name, repr(control.value) None None http://search.usa.gov/search hidden v:project 'firstgov' text query '' radio affiliate ['nws.noaa.gov'] submit None 'Go' None None http://forecast.weather.gov/zipcity.php text inputstring 'City, St' submit Go2 'Go' 'jump' 'jump' http://www.weather.gov/ select menu ['http://www.weather.gov/alerts-beta/'] button None None
Here, mechanize has helped us avoid reading any HTML at all. Of course, pages with very obscure form names and fields might make it very difficult to look at a list of forms like this and decide which is the form we see on the page that we want to submit; in those cases, inspecting the HTML ourselves can be helpful, or—if you use Google Chrome, or Firefox with Firebug installed—right-clicking the form and selecting “Inspect Element” to jump right to its element in the document tree.
Once we have determined that we need the zipcity.php form, we can write a program like that shown in Listing 10–2. You can see that at no point does it build a set of form fields manually itself, as was necessary in our previous listing. Instead, it simply loads the front page, sets the one field value that we care about, and then presses the form's submit button. Note that since this HTML form did not specify a name, we had to create our own filter function—the lambda function in the listing—to choose which of the three forms we wanted.
Listing 10–2. Submitting a Form with mechanize
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 10 - fetch_mechanize.py # Submitting a form and retrieving a page with mechanize import mechanize br = mechanize.Browser() br.open('http://www.weather.gov/') br.select_form(predicate=lambda(form): 'zipcity' in form.action) br['inputstring'] = 'Phoenix, AZ' response = br.submit() content = response.read() open('phoenix.html', 'w').write(content)
Many mechanize users instead choose to select forms by the order in which they appear in the page—in which case we could have called select_form(nr=1). But I prefer not to rely on the order, since the real identity of a form is inherent in the action that it performs, not its location on a page.
You will see immediately the problem with using mechanize for this kind of simple task: whereas Listing 10–1 was able to fetch the page we wanted with a single HTTP request, Listing 10–2 requires two round-trips to the web site to do the same task. For this reason, I avoid using mechanize for simple form submission. Instead, I keep it in reserve for the task at which it really shines: logging on to web sites like banks, which set cookies when you first arrive at their front page and require those cookies to be present as you log in and browse your accounts. Since these web sessions require a visit to the front page anyway, no extra round-trips are incurred by using mechanize.
The Structure of Web Pages
There is a veritable glut of online guides and published books on the subject of HTML, but a few notes about the format would seem to be appropriate here for users who might be encountering the format for the first time.
The Hypertext Markup Language (HTML) is one of many markup dialects built atop the Standard Generalized Markup Language (SGML), which bequeathed to the world the idea of using thousands of angle brackets to mark up plain text. Inserting bold and italics into a format like HTML is as simple as typing eight angle brackets:
The <b>very</b> strange book <i>Tristram Shandy</i>.
In the terminology of SGML, the strings <b> and </b> are each tags—they are, in fact, an opening and a closing tag—and together they create an element that contains the text very inside it. Elements can contain text as well as other elements, and can define a series of key/value attribute pairs that give more information about the element:
<p content="personal">I am reading <i document="play">Hamlet</i>.</p>
There is a whole subfamily of markup languages based on the simpler Extensible Markup Language (XML), which takes SGML and removes most of its special cases and features to produce documents that can be generated and parsed without knowing their structure ahead of time. The problem with SGML languages in this regard—and HTML is one particular example—is that they expect parsers to know the rules about which elements can be nested inside which other elements, and this leads to constructions like this unordered list <ul>, inside which are several list items <li>:
<ul><li>First<li>Second<li>Third<li>Fourth</ul>
At first this might look like a series of <li> elements that are more and more deeply nested, so that the final word here is four list elements deep. But since HTML in fact says that <li> elements cannot nest, an HTML parser will understand the foregoing snippet to be equivalent to this more explicit XML string:
<ul><li>First</li><li>Second</li><li>Third</li><li>Fourth</li></ul>
And beyond this implicit understanding of HTML that a parser must possess are the twin problems that, first, various browsers over the years have varied wildly in how well they can reconstruct the document structure when given very concise or even deeply broken HTML; and, second, most web page authors judge the quality of their HTML by whether their browser of choice renders it correctly. This has resulted not only in a World Wide Web that is full of sites with invalid and broken HTML markup, but also in the fact that the permissiveness built into browsers has encouraged different flavors of broken HTML among their different user groups.
If HTML is a new concept to you, you can find abundant resources online. Here are a few documents that have been longstanding resources in helping programmers learn the format:
- https://www.w3.org/MarkUp/Guide/
https://www.w3.org/MarkUp/Guide/Advanced.html
https://www.w3.org/MarkUp/Guide/Style
The brief Bare Bones Guide, and the long and verbose HTML standard itself, are good resources to have when trying to remember an element name or the name of a particular attribute value:
- https://werbach.com/barebones/barebones.html
https://www.w3.org/TR/REC-html40/
When building your own web pages, try to install a real HTML validator in your editor, IDE, or build process, or test your web site once it is online by submitting it to
- https://validator.w3.org/
You might also want to consider using the tidy tool, which can also be integrated into an editor or build process:
- https://tidy.sourceforge.net/
We will now turn to that weather forecast for Phoenix, Arizona, that we downloaded earlier using our scripts (note that we will avoid creating extra traffic for the NWS by running our experiments against this local file), and we will learn how to extract actual data from HTML.
Three Axes
Parsing HTML with Python requires three choices:
- The parser you will use to digest the HTML, and try to make sense of its tangle of opening and closing tags
- The API by which your Python program will access the tree of concentric elements that the parser built from its analysis of the HTML page
- What kinds of selectors you will be able to write to jump directly to the part of the page that interests you, instead of having to step into the hierarchy one element at a time
The issue of selectors is a very important one, because a well-written selector can unambiguously identify an HTML element that interests you without your having to touch any of the elements above it in the document tree. This can insulate your program from larger design changes that might be made to a web site; as long as the element you are selecting retains the same ID, name, or whatever other property you select it with, your program will still find it even if after the redesign it is several levels deeper in the document.
I should pause for a second to explain terms like “deeper,” and I think the concept will be clearest if we reconsider the unordered list that was quoted in the previous section. An experienced web developer looking at that list rearranges it in her head, so that this is what it looks like:
<ul> <li>First</li> <li>Second</li> <li>Third</li> <li>Fourth</li> </ul>
Here the <ul> element is said to be a “parent” element of the individual list items, which “wraps” them and which is one level “above” them in the whole document. The <li> elements are “siblings” of one another; each is a “child” of the <ul> element that “contains” them, and they sit “below” their parent in the larger document tree. This kind of spatial thinking winds up being very important for working your way into a document through an API.
In brief, here are your choices along each of the three axes that were just listed:
- The most powerful, flexible, and fastest parser at the moment appears to be the
HTMLParserthat comes withlxml; the next most powerful is the longtime favorite BeautifulSoup (I see that its author has, in his words, “abandoned” the new 3.1 version because it is weaker when given broken HTML, and recommends using the 3.0 series until he has time to release 3.2); and coming in dead last are the parsing classes included with the Python Standard Library, which no one seems to use for serious screen scraping. - The best API for manipulating a tree of HTML elements is ElementTree, which has been brought into the Standard Library for use with the Standard Library parsers, and is also the API supported by
lxml; BeautifulSoup supports an API peculiar to itself; and a pair of ancient, ugly, event-based interfaces to HTML still exist in the Python Standard Library. - The
lxmllibrary supports two of the major industry-standard selectors: CSS selectors and XPath query language; BeautifulSoup has a selector system all its own, but one that is very powerful and has powered countless web-scraping programs over the years.
Given the foregoing range of options, I recommend using lxml when doing so is at all possible—installation requires compiling a C extension so that it can accelerate its parsing using libxml2—and using BeautifulSoup if you are on a machine where you can install only pure Python. Note that lxml is available as a pre-compiled package named python-lxml on Ubuntu machines, and that the best approach to installation is often this command line:
STATIC_DEPS=true pip install lxml
And if you consult the lxml documentation, you will find that it can optionally use the BeautifulSoup parser to build its own ElementTree-compliant trees of elements. This leaves very little reason to use BeautifulSoup by itself unless its selectors happen to be a perfect fit for your problem; we will discuss them later in this chapter.
But the state of the art may advance over the years, so be sure to consult its own documentation as well as recent blogs or Stack Overflow questions if you are having problems getting it to compile.
From the Future
The BeautifulSoup project has recovered! While the text below — written in late 2010 — has to carefully avoid the broken 3.2 release in favor of 3.0, BeautifulSoup has now released a rewrite named beautifulsoup4 on the Python Package Index that works with both Python 2 and 3. Once installed, simply import it like this:
from bs4 import BeautifulSoup
I just ran a test, and it reads the malformed phoenix.html page perfectly.
Diving into an HTML Document
The tree of objects that a parser creates from an HTML file is often called a Document Object Model, or DOM, even though this is officially the name of one particular API defined by the standards bodies and implemented by browsers for the use of JavaScript running on a web page.
The task we have set for ourselves, you will recall, is to find the current conditions, temperature, and humidity in the phoenix.html page that we have downloaded. Here is an excerpt: Listing 10–3, which focuses on the pane that we are interested in.
Listing 10–3. Excerpt from the Phoenix Forecast Page
<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN"><html><head> <title>7-Day Forecast for Latitude 33.45°N and Longitude 112.07°W (Elev. 1132 ft)</title><link rel="STYLESHEET" type="text/css" href="fonts/main.css"> ... <table cellspacing="0" cellspacing="0" border="0" width="100%"><tr align="center"><td><table width='100%' border='0'> <tr> <td align ='center'> <span class='blue1'>Phoenix, Phoenix Sky Harbor International Airport</span><br> Last Update on 29 Oct 7:51 MST<br><br> </td> </tr> <tr> <td colspan='2'> <table cellspacing='0' cellpadding='0' border='0' align='left'> <tr> <td class='big' width='120' align='center'> <font size='3' color='000066'> A Few Clouds<br> <br>71°F<br>(22°C)</td> </font><td rowspan='2' width='200'><table cellspacing='0' cellpadding='2' border='0' width='100%'> <tr bgcolor='#b0c4de'> <td><b>Humidity</b>:</td> <td align='right'>30 %</td> </tr> <tr bgcolor='#ffefd5'> <td><b>Wind Speed</b>:</td><td align='right'>SE 5 MPH<br> </td> </tr> <tr bgcolor='#b0c4de'> <td><b>Barometer</b>:</td><td align='right' nowrap>30.05 in (1015.90 mb)</td></tr> <tr bgcolor='#ffefd5'> <td><b>Dewpoint</b>:</td><td align='right'>38°F (3°C)</td> </tr> </tr> <tr bgcolor='#ffefd5'> <td><b>Visibility</b>:</td><td align='right'>10.00 Miles</td> </tr> <tr><td nowrap><b><a href='http://www.wrh.noaa.gov/total_forecast/other_obs.php?wfo=psr&zone=AZZ023' class='link'>More Local Wx:</a></b> </td> <td nowrap align='right'><b><a href='http://www.wrh.noaa.gov/mesowest/getobext.php?wfo=psr&sid=KPHX&num=72' class='link'>3 Day History:</a></b> </td></tr> </table> ...
There are two approaches to narrowing your attention to the specific area of the document in which you are interested. You can either search the HTML for a word or phrase close to the data that you want, or, as we mentioned previously, use Google Chrome or Firefox with Firebug to “Inspect Element” and see the element you want embedded in an attractive diagram of the document tree. Figure 10–2 shows Google Chrome with its Developer Tools pane open following an Inspect Element command: my mouse is poised over the <font> element that was brought up in its document tree, and the element itself is highlighted in blue on the web page itself.
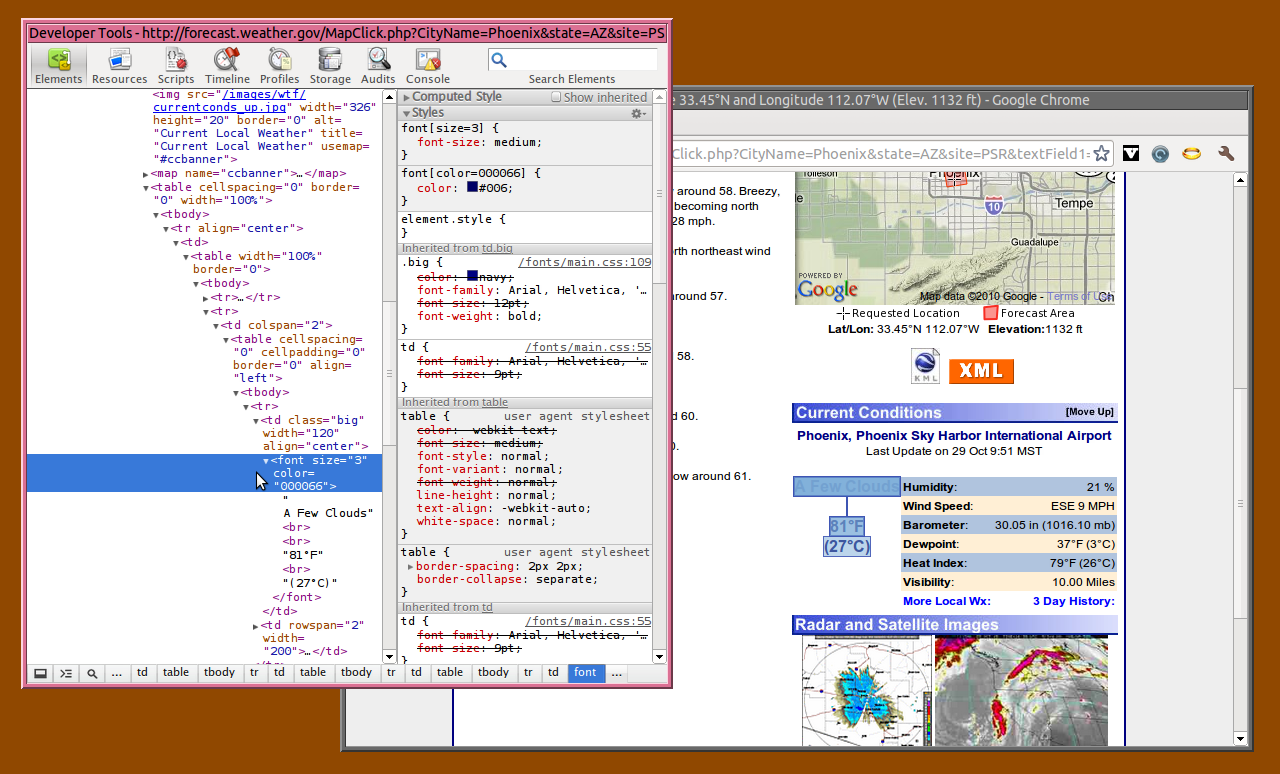
Figure 10–2. Examining Document Elements in the Browser
(click to enlarge)
Note that Google Chrome does have an annoying habit of filling in “conceptual” tags that are not actually present in the source code, like the <tbody> tags that you can see in every one of the tables shown here. For that reason, I look at the actual HTML source before writing my Python code; I mainly use Chrome to help me find the right places in the HTML.
We will want to grab the text “A Few Clouds” as well as the temperature before turning our attention to the table that sits to this element's right, which contains the humidity.
A properly indented version of the HTML page that you are scraping is good to have at your elbow while writing code. I have included phoenix-tidied.html with the source code bundle for this chapter so that you can take a look at how much easier it is to read!
You can see that the element displaying the current conditions in Phoenix sits very deep within the document hierarchy. Deep nesting is a very common feature of complicated page designs, and that is why simply walking a document object model can be a very verbose way to select part of a document—and, of course, a brittle one, because it will be sensitive to changes in any of the target element's parent. This will break your screen-scraping program not only if the target web site does a redesign, but also simply because changes in the time of day or the need for the site to host different kinds of ads can change the layout subtly and ruin your selector logic.
To see how direct document-object manipulation would work in this case, we can load the raw page directly into both the lxml and BeautifulSoup systems.
>>> import lxml.etree >>> parser = lxml.etree.HTMLParser(encoding='utf-8') >>> tree = lxml.etree.parse('phoenix.html', parser)
The need for a separate parser object here is because, as you might guess from its name, lxml is natively targeted at XML files.
>>> from BeautifulSoup import BeautifulSoup >>> soup = BeautifulSoup(open('phoenix.html')) Traceback (most recent call last): ... HTMLParseError: malformed start tag, at line 96, column 720
What on earth? Well, look, the National Weather Service does not check or tidy its HTML! I might have chosen a different example for this book if I had known, but since this is a good illustration of the way the real world works, let's press on. Jumping to line 96, column 720 of phoenix.html, we see that there does indeed appear to be some broken HTML:
<a href="http://www.weather.gov"<u>www.weather.gov</u></a>
You can see that the <u> tag starts before a closing angle bracket has been encountered for the <a> tag. But why should BeautifulSoup care? I wonder what version I have installed.
>>> BeautifulSoup.__version__ '3.1.0'
Well, drat. I typed too quickly and was not careful to specify a working version when I ran pip to install BeautifulSoup into my virtual environment. Let's try again:
$ pip install BeautifulSoup==3.0.8.1
And now the broken document parses successfully:
>>> from BeautifulSoup import BeautifulSoup >>> soup = BeautifulSoup(open('phoenix.html'))
That is much better!
Now, if we were to take the approach of starting at the top of the document and digging ever deeper until we find the node that we are interested in, we are going to have to generate some very verbose code. Here is the approach we would have to take with lxml:
>>> fonttag = tree.find('body').find('div').findall('table')[3] \ ... .findall('tr')[1].find('td').findall('table')[1].find('tr') \ ... .findall('td')[1].findall('table')[1].find('tr').find('td') \ ... .find('table').findall('tr')[1].find('td').find('table') \ ... .find('tr').find('td').find('font') >>> fonttag.text '\nA Few Clouds'
An attractive syntactic convention lets BeautifulSoup handle some of these steps more beautifully:
>>> fonttag = soup.body.div('table', recursive=False)[3] \ ... ('tr', recursive=False)[1].td('table', recursive=False)[1].tr \ ... ('td', recursive=False)[1]('table', recursive=False)[1].tr.td \ ... .table('tr', recursive=False)[1].td.table \ ... .tr.td.font >>> fonttag.text u'A Few Clouds71°F(22°C)'
BeautifulSoup lets you choose the first child element with a given tag by simply selecting the attribute .tagname, and lets you receive a list of child elements with a given tag name by calling an element like a function—you can also explicitly call the method findAll()—with the tag name and a recursive option telling it to pay attention just to the children of an element; by default, this option is set to True, and BeautifulSoup will run off and find all elements with that tag in the entire sub-tree beneath an element!
Anyway, two lessons should be evident from the foregoing exploration.
First, both lxml and BeautifulSoup provide attractive ways to quickly grab a child element based on its tag name and position in the document.
Second, we clearly should not be using such primitive navigation to try descending into a real-world web page! I have no idea how code like the expressions just shown can easily be debugged or maintained; they would probably have to be re-built from the ground up if anything went wrong with them—they are a painful example of write-once code.
And that is why selectors that each screen-scraping library supports are so critically important: they are how you can ignore the many layers of elements that might surround a particular target, and dive right in to the piece of information you need.
Figuring out how HTML elements are grouped, by the way, is much easier if you either view HTML with an editor that prints it as a tree, or if you run it through a tool like HTML tidy from W3C that can indent each tag to show you which ones are inside which other ones:
$ tidy phoenix.html > phoenix-tidied.html
You can also use either of these libraries to try tidying the code, with a call like one of these:
lxml.html.tostring(html) soup.prettify()
See each library's documentation for more details on using these calls.
Selectors
A selector is a pattern that is crafted to match document elements on which your program wants to operate. There are several popular flavors of selector, and we will look at each of them as possible techniques for finding the current-conditions <font> tag in the National Weather Service page for Phoenix. We will look at three:
- People who are deeply XML-centric prefer XPath expressions, which are a companion technology to XML itself and let you match elements based on their ancestors, their own identity, and textual matches against their attributes and text content. They are very powerful as well as quite general.
- If you are a web developer, then you probably link to CSS selectors as the most natural choice for examining HTML. These are the same patterns used in Cascading Style Sheets documents to describe the set of elements to which each set of styles should be applied.
- Both
lxmland BeautifulSoup, as we have seen, provide a smattering of their own methods for finding document elements.
Here are standards and descriptions for each of the selector styles just described— first, XPath:
- https://www.w3.org/TR/xpath/
https://lxml.de/tutorial.html#using-xpath-to-find-text
https://lxml.de/xpathxslt.html
And here are some CSS selector resources:
- https://www.w3.org/TR/CSS2/selector.html
https://lxml.de/cssselect.html
And, finally, here are links to documentation that looks at selector methods peculiar to lxml and BeautifulSoup:
- https://lxml.de/tutorial.html#elementpath
https://www.crummy.com/software/BeautifulSoup/bs3/documentation.html#Searching%20the%20Parse%20Tree
The National Weather Service has not been kind to us in constructing this web page. The area that contains the current conditions seems to be constructed entirely of generic untagged elements; none of them have id or class values like currentConditions or temperature that might help guide us to them.
Well, what are the features of the elements that contain the current weather conditions in Listing 10–3? The first thing I notice is that the enclosing <td> element has the class "big". Looking at the page visually, I see that nothing else seems to be of exactly that font size; could it be so simple as to search the document for every <td> with this CSS class? Let us try, using a CSS selector to begin with:
>>> from lxml.cssselect import CSSSelector >>> sel = CSSSelector('td.big') >>> sel(tree) [<Element td at b72ec0a4>]
Perfect! It is also easy to grab elements with a particular class attribute using the peculiar syntax of BeautifulSoup:
>>> soup.find('td', 'big') <td class="big" width="120" align="center"> <font size="3" color="000066"> A Few Clouds<br /> <br />71°F<br />(22°C)</font></td>
Writing an XPath selector that can find CSS classes is a bit difficult since the class="" attribute contains space-separated values and we do not know, in general, whether the class will be listed first, last, or in the middle.
>>> tree.xpath(".//td[contains(concat(' ', normalize-space(@class), ' '), ' big ')]") [<Element td at a567fcc>]
This is a common trick when using XPath against HTML: by prepending and appending spaces to the class attribute, the selector assures that it can look for the target class name with spaces around it and find a match regardless of where in the list of classes the name falls.
Selectors, then, can make it simple, elegant, and also quite fast to find elements deep within a document that interest us. And if they break because the document is redesigned or because of a corner case we did not anticipate, they tend to break in obvious ways, unlike the tedious and deep procedure of walking the document tree that we attempted first.
Once you have zeroed in on the part of the document that interests you, it is generally a very simple matter to use the ElementTree or the old BeautifulSoup API to get the text or attribute values you need. Compare the following code to the actual tree shown in Listing 10–3:
>>> td = sel(tree)[0] >>> td.find('font').text '\nA Few Clouds' >>> td.find('font').findall('br')[1].tail u'71°F'
If you are annoyed that the first string did not return as a Unicode object, you will have to blame the ElementTree standard; the glitch has been corrected in Python 3! Note that ElementTree thinks of text strings in an HTML file not as entities of their own, but as either the .text of its parent element or the .tail of the previous element. This can take a bit of getting used to, and works like this:
<p> My favorite play is # the <p> element's .text <i> Hamlet # the <i> element's .text </i> which is not really # the <i> element's .tail <b> Danish # the <b> element's .text </b> but English. # the <b> element's .tail </p>
This can be confusing because you would think of the three words favorite and really and English as being at the same “level” of the document—as all being children of the <p> element somehow—but lxml considers only the first word to be part of the text attached to the <p> element, and considers the other two to belong to the tail texts of the inner <i> and <b> elements. This arrangement can require a bit of contortion if you ever want to move elements without disturbing the text around them, but leads to rather clean code otherwise, if the programmer can keep a clear picture of it in her mind.
BeautifulSoup, by contrast, considers the snippets of text and the <br> elements inside the <font> tag to all be children sitting at the same level of its hierarchy. Strings of text, in other words, are treated as phantom elements. This means that we can simply grab our text snippets by choosing the right child nodes:
>>> td = soup.find('td', 'big') >>> td.font.contents[0] u'\nA Few Clouds' >>> td.font.contents[4] u'71°F'
Through a similar operation, we can direct either lxml or BeautifulSoup to the humidity datum. Since the word Humidity: will always occur literally in the document next to the numeric value, this search can be driven by a meaningful term rather than by something as random as the big CSS tag. See Listing 10–4 for a complete screen-scraping routine that does the same operation first with lxml and then with BeautifulSoup.
This complete program, which hits the National Weather Service web page for each request, takes the city name on the command line:
$ python weather.py Springfield, IL Condition: Traceback (most recent call last): ... AttributeError: 'NoneType' object has no attribute 'text'
And here you can see, superbly illustrated, why screen scraping is always an approach of last resort and should always be avoided if you can possibly get your hands on the data some other way: because presentation markup is typically designed for one thing—human readability in browsers—and can vary in crazy ways depending on what it is displaying.
What is the problem here? A short investigation suggests that the NWS page includes only a <font> element inside of the <tr> if—and this is just a guess of mine, based on a few examples—the description of the current conditions is several words long and thus happens to contain a space. The conditions in Phoenix as I have written this chapter are “A Few Clouds,” so the foregoing code has worked just fine; but in Springfield, the weather is “Fair” and therefore does not need a <font> wrapper around it, apparently.
Listing 10–4. Completed Weather Scraper
#!/usr/bin/env python # Foundations of Python Network Programming - Chapter 10 - weather.py # Fetch the weather forecast from the National Weather Service. import sys, urllib, urllib2 import lxml.etree from lxml.cssselect import CSSSelector from BeautifulSoup import BeautifulSoup if len(sys.argv) < 2: print >>sys.stderr, 'usage: weather.py CITY, STATE' exit(2) data = urllib.urlencode({'inputstring': ' '.join(sys.argv[1:])}) info = urllib2.urlopen('http://forecast.weather.gov/zipcity.php', data) content = info.read() # Solution #1 parser = lxml.etree.HTMLParser(encoding='utf-8') tree = lxml.etree.fromstring(content, parser) big = CSSSelector('td.big')(tree)[0] if big.find('font') is not None: big = big.find('font') print 'Condition:', big.text.strip() print 'Temperature:', big.findall('br')[1].tail tr = tree.xpath('.//td[b="Humidity"]')[0].getparent() print 'Humidity:', tr.findall('td')[1].text print # Solution #2 soup = BeautifulSoup(content) # doctest: +SKIP big = soup.find('td', 'big') if big.font is not None: big = big.font print 'Condition:', big.contents[0].string.strip() temp = big.contents[3].string or big.contents[4].string # can be either print 'Temperature:', temp.replace('°', ' ') tr = soup.find('b', text='Humidity').parent.parent.parent print 'Humidity:', tr('td')[1].string print
If you look at the final form of Listing 10–4, you will see a few other tweaks that I made as I noticed changes in format with different cities. It now seems to work against a reasonable selection of locations; again, note that it gives the same report twice, generated once with lxml and once with BeautifulSoup:
$ python weather.py Springfield, IL Condition: Fair Temperature: 54 °F Humidity: 28 %</code> <code>Condition: Fair Temperature: 54 F Humidity: 28 % $ python weather.py Grand Canyon, AZ Condition: Fair Temperature: 67°F Humidity: 28 % Condition: Fair Temperature: 67 F Humidity: 28 %
You will note that some cities have spaces between the temperature and the F, and others do not. No, I have no idea why. But if you were to parse these values to compare them, you would have to learn every possible variant and your parser would have to take them into account.
I leave it as an exercise to the reader to determine why the web page currently displays the word “NULL”—you can even see it in the browser—for the temperature in Elk City, Oklahoma. Maybe that location is too forlorn to even deserve a reading? In any case, it is yet another special case that you would have to treat sanely if you were actually trying to repackage this HTML page for access from an API:
$ python weather.py Elk City, OK
Condition: Fair and Breezy
Temperature: NULL
Humidity: NA
Condition: Fair and Breezy
Temperature: NULL
Humidity: NA
I also leave as an exercise to the reader the task of parsing the error page that comes up if a city cannot be found, or if the Weather Service finds it ambiguous and prints a list of more specific choices!
Summary
Although the Python Standard Library has several modules related to SGML and, more specifically, to HTML parsing, there are two premier screen-scraping technologies in use today: the fast and powerful lxml library that supports the standard Python “ElementTree” API for accessing trees of elements, and the quirky BeautifulSoup library that has powerful API conventions all its own for querying and traversing a document.
If you use BeautifulSoup before 3.2 comes out, be sure to download the most recent 3.0 version; the 3.1 series, which unfortunately will install by default, is broken and chokes easily on HTML glitches.
Screen scraping is, at bottom, a complete mess. Web pages vary in unpredictable ways even if you are browsing just one kind of object on the site—like cities at the National Weather Service, for example.
To prepare to screen scrape, download a copy of the page, and use HTML tidy, or else your screen-scraping library of choice, to create a copy of the file that your eyes can more easily read. Always run your program against the ugly original copy, however, lest HTML tidy fixes something in the markup that your program will need to repair!
Once you find the data you want in the web page, look around at the nearby elements for tags, classes, and text that are unique to that spot on the screen. Then, construct a Python command using your scraping library that looks for the pattern you have discovered and retrieves the element in question. By looking at its children, parents, or enclosed text, you should be able to pull out the data that you need from the web page intact.
When you have a basic script working, continue testing it; you will probably find many edge cases that have to be handled correctly before it becomes generally useful. Remember: when possible, always use true APIs, and treat screen scraping as a technique of last resort!
©2010 by Brandon Rhodes and John Goerzen

